
- Published on
Remember AI Engineers, Your Evals Are Your Product
- Authors

- Name
- Sohan Kshirsagar
- @SohanKshirsagar

- Name
- Marcel Tan
- @Marcel7an
Eval-Driven Development
What differentiates the hundreds of AI-powered receptionists in the market? The dozens of AI coding agents making the rounds on X? Or the wave of AI writing tools?
It’s simple: their evals.
For AI-native companies, your evals are your product. Which leads to a controversial opinion: you should not outsource your evals to an external framework.
If you want to understand the underlying qualities of any AI-native product, the best place to start is looking at how the company evaluates its system.
As an AI engineer, you can’t improve what you can’t measure. So without reliable evals, you’re basically flying blind.
At the same time, the rate of improvement we're seeing with LLMs means that heavy, rigid evals can’t keep up with the speed at which modern AI teams have to iterate. Your evals have to be lightweight if you want to do this at scale across a constantly evolving system.
We realized this early while building Tusk, our AI unit test generation agent.
However, when we started building our evals, we ran into three challenges:
1. We’re a rapidly evolving startup
- Our AI workflow, codebase, and features are changing by the hour. Writing rigid evals today could be out of date tomorrow.
- Lightweight, flexible evals aren’t just a nice-to-have. They are essential.
2. Our AI agent is complex
- Tusk is not a single prompt → response product. It’s a system with dozens of interconnected tools, workflow steps, and logical branches.
- While end-to-end evals are useful sanity checks, they don’t help us iterate on specific components of our AI test generation workflow.
3. We deal with unstructured I/O
- Each part of the system has its own inputs and outputs that vary in structure.
- And back to point 1, the inputs and outputs are constantly changing.
If you’re building an agentic AI product today, I'm certain that you're hitting at least one of these walls. Traditional eval tools are too rigid for fast moving teams. So we sought to solve this internally.
One of the biggest unlocks came from how we wrote our code.
Better Evals With Functional Programming
One reason our evals worked so well was because we made our system as functional as possible. This meant actively avoiding object-oriented programming.
Whenever possible, each part of the AI system was built as a function: input → output. No global state, dependency injection, or complex class hierarchies.
Why does this matter for evals?
- It’s easy to isolate a component and run it on a dataset.
- You don’t need to spin up the whole app or fake an entire service—just call the function.
When your code is written this way, writing evals is just like writing unit tests. If your system is a web of classes and injected dependencies, it becomes painful to extract clean inputs/outputs for evals.
Example: Test File Incorporation
Let’s look at one particular part of our system: test file incorporation.
For context, this refers to how Tusk consolidates individual tests into a single test file.
Tusk doesn’t just blindly generate unit tests. Instead, our AI tool takes your existing test files and intelligently incorporates the new test cases, making sure the formatting, imports, and structure stay intact.
The incorporation step is an important part of our value prop—developers want their test files clean, readable, and executable.
To get this right, we needed to try multiple approaches and compare them on reliability and latency. Without a flexible eval setup, it was almost impossible to know if one approach was better than another.
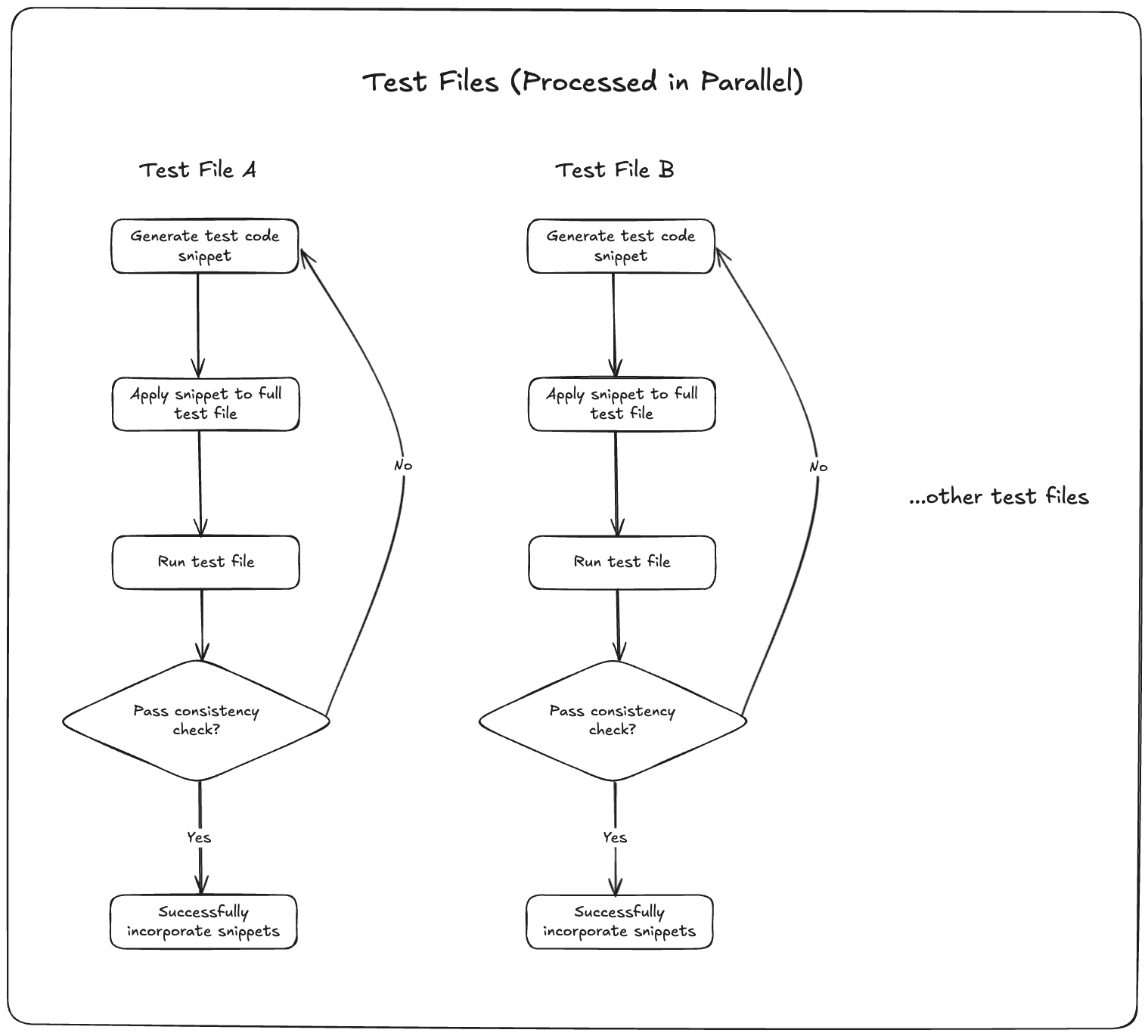
Tusk's test file incorporation workflow
The Lightweight Eval
The breakthrough came when we realized we didn’t need some massive evaluation infrastructure. We just needed:
- A clear contract: What goes in, what should come out?
- A way to evaluate the outputs
- A way to view the results quickly
So we wrote simple scripts that would:
- Take the part of the workflow we want to evaluate (say, test incorporation)
- Create a dataset of inputs and outputs
- Run the component across this dataset
- Use Cursor or Claude, to quickly generate a visual HTML report showing:
- The input
- The agent’s output
- Eval results
We dropped the report into a folder, opened it in our browser, and boom—we had a clear visual snapshot of how that component was performing across the dataset.
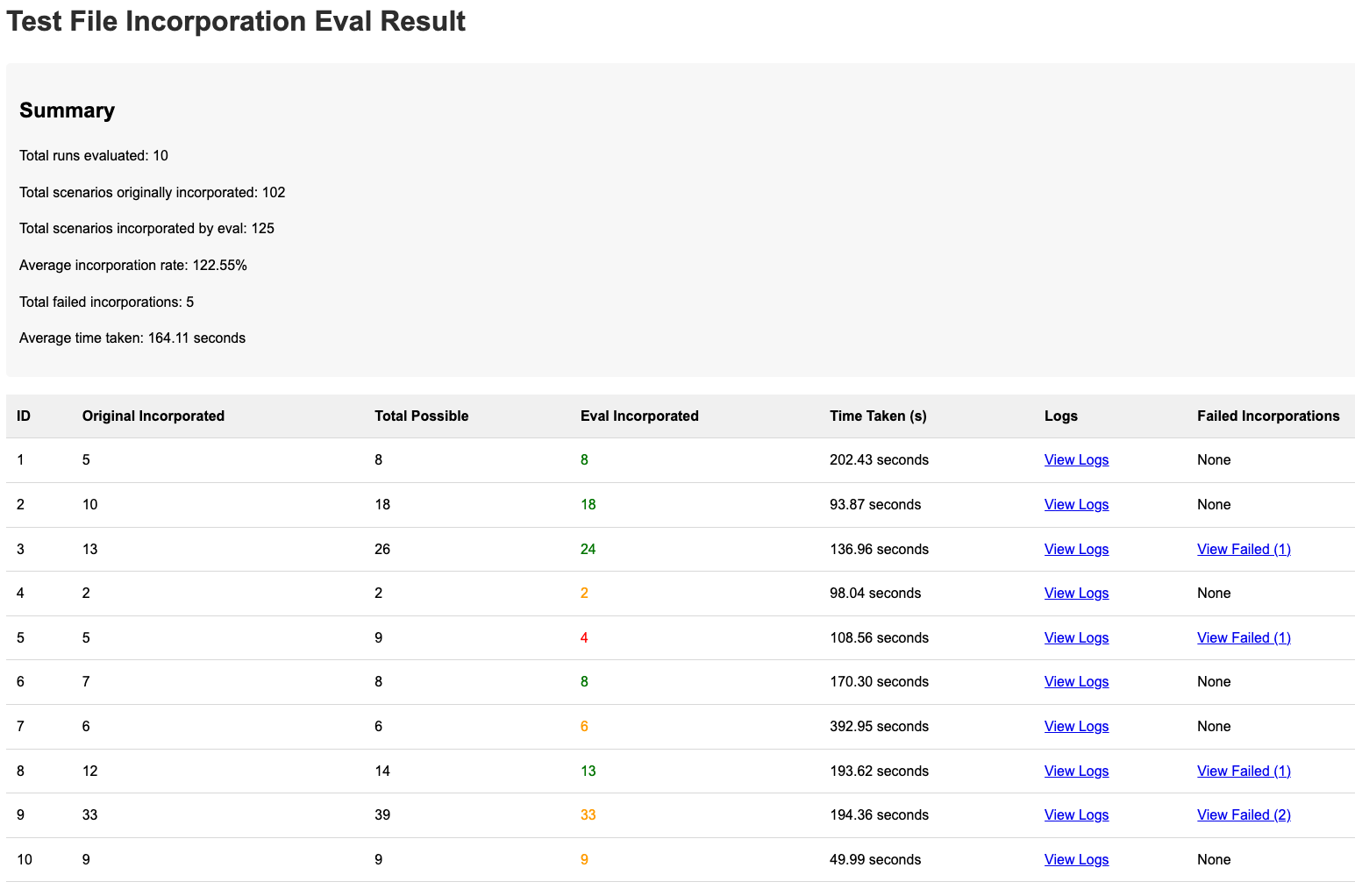
Tusk's HTML report for evaluating test file incorporation
Why This Works
These HTML evals aren’t fancy, but they work. Here’s why:
- Speed
- With a functional code base and AI powered code editor, you can create these eval scripts in under 5 minutes
- Flexibility
- If the inputs/outputs change, just update the dataset and use Cursor/Claude to quickly generate a new HTML report of the eval output
- Cost-efficient
- No external infra or tools. Just scripts and files.
Once we had this in place, we started using it everywhere:
- Trying three different strategies for formatting incorporated test cases? Run them all, drop them in a report, and visually compare the results.
- Wondering if a new model helps or hurts a specific part of the pipeline? Run the evals and check the reports.
Instead of relying on intuition or scattered examples, we had a system of truth—even if it was just HTML files in a folder.
Final Note
One thing I hear a lot when talking to AI engineers early in their journey is that it's tedious to perform evals.
While a vibes-based approach to building AI products may work for getting a minimum viable product, making it production-ready almost always means following eval-driven development.
If there's one thing to take away from this post, it's that LLM evals don’t have to be heavyweight. They just need to be useful. For us, that meant:
- Keeping code functional
- Keeping evals lightweight
- Using tools like Cursor or Claude to automate HTML generation
In a world where your agents are evolving rapidly, the ability to spin up evals in minutes is critical. Our HTML reports have helped us iterate and ship faster while maintaining high product quality.
If you’re stuck on how to evaluate your agent, try starting with these lightweight evals. You'll be surprised how far you get without excessive overhead.
Let me know if you’ve tried something similar—I’d love to swap notes.
