
- Published on
TypeScript AI Unit Test Generators: Tusk v Cursor v Claude
- Authors

- Name
- Marcel Tan
- @Marcel7an
Contents
Hey there, I'm Marcel Tan. 👋
- I'm the co-founder and CEO of Tusk. My co-founder Sohil and I built one of the first publicly accessible AI coding agents back in Nov 2023.
- Tusk is a Y Combinator-backed company that helps developers generate unit and integration tests for PR/MRs.
- We serve engineering teams from top venture-backed startups all the way to enterprise companies with hundreds of engineers.
Introduction
The recent releases of SOTA models like GPT 4.5, Claude 3.7 Sonnet, and Gemini 2.5 Pro have finally unlocked the value of autonomous agents for companies with mature, complex codebases.
These models power some of the most popular AI coding agents today, like Cursor Agent, Claude Code, and Tusk.
In this post, I will be focusing specifically on using agents to generate unit tests to improve software reliability.
LLM-powered test generation is still a relatively nascent space. Tusk stands out as one of the only verticalized AI coding agents for unit test generation. Most coding agents are built to serve a wide breadth of code-related use cases, instead of going deep on one.
We did a poll of senior and staff-level software engineers to see what general-purpose coding agents were most popular with developers for generating automated tests. Cursor and Claude Code were the two most common answers.
Naturally, we were interested in comparing Tusk's test generation capabilities to that of Cursor Agent and Claude Code. We not only wanted to see how accurately each agent generated tests, but also whether they were able to uncover hidden bugs.
These products are complementary to one another since they have different strengths and limitations. The curiosity driving this post is whether the delta of using a verticalized agent over a general-purpose agent for a single use case makes it worth the squeeze.
Summary
We ran the three AI agents multiple times (n = 10) on an identical PR using the same prompts.
The PR contained code changes that introduced a subtle bug to the codebase. We wanted to find for each agent their bug detection rate, coverage depth, level of codebase awareness, and test variety.
What we found was that all three agents were able to generate executable test code. Our analysis, however, showed significant disparities between agents in both bug detection capabilities and test code quality.
Tusk demonstrated greater consistency in following test set-up and mocking best practices. Tusk also correctly identified the bug in the PR in an overwhelming majority of its test generation runs, whereas Cursor Agent and Claude Code did not identify the bug in all of their test generation runs.
Methodology
We employed the following methodology to do a comparative analysis of Tusk, Cursor Agent, and Claude Code when it came to unit test generation:
- Identical code repository used
- Identical PR and commit SHA that contains a boundary condition bug
- Consistent agent prompting approach
- 10 independent test generation runs for each AI agent
The code repository in question was a clone of our Tusk repo, which is a mature web app with two years of commits.
The commit we used for this comparison was from an example PR for enforcing seat limits for clients (i.e., organizations). We chose this specific example because it 1) was a common feature for growth-stage and enterprise companies, 2) required mocking data structures, and 3) had enough complexity to present edge cases.
We did our best to make sure that the prompts and context provided as input were consistent across the three AI agents. It is worth noting that the inputs provided to the agents were not identical because each agent has a unique feature set.
Tusk, for example, provides coverage metrics out of the box and utilizes project and file-based system prompts that are abstracted away from its UI/UX. Cursor Agent, on the other hand, uses its Rules for AI to get global and project context, while Claude Code relies on its (typically LLM-generated) CLAUDE.md file for codebase context.
Regardless, these differences in input naturally arise as part of the developer experience of each agent. As such, the test generation results are a realistic representation of the agents' output in the real world.
System Message
Below is an abridged version of the system message provided. It outlines the test scenario guidelines that the agent should follow when generating tests.
You are an experienced senior software engineer evaluating test scenarios suggested by reviewers for your pull request. Assess each scenario's validity and importance based on the codebase context.
Classify test scenarios as:
- High importance (critical to system integrity)
- Low importance (helpful but not critical)
- Invalid (not applicable or redundant)
Prioritize scenarios involving data flow integrity, security concerns, core business logic, error handling, and those with broad impact. Ground your assessment in factual code constraints and the PR's specific purpose.
Favor quality over quantity in test coverage, rejecting implausible edge cases while acknowledging genuinely important scenarios that could prevent incidents.
Prompt
This is the user message provided to each agent:
Generate unit tests for the following code changes given the test scenario guidelines. Once you've generated the unit tests, in backend, run
nvm useand thennpm run testto show me whether the tests are passing or failing.
Example PR
Title: [TUS-914] Enforce seat limit
Description: Prevent activation of seats if client is not under seat limit
Code changes:
diff --git a/backend/src/services/UsersService.ts b/backend/src/services/UsersService.ts
index 36d43317b..72f9e2123 100644
--- a/backend/src/services/UsersService.ts
+++ b/backend/src/services/UsersService.ts
@@ -334,7 +334,11 @@ export class UsersService {
}
async activateSeat(seatId: string): Promise<void> {
- await this.dbRepos.seatRepository.update(seatId, { active: true });
+ const hasAvailableSeats = await this.isClientUnderSeatLimit(this.requestContext.clientId);
+
+ if (hasAvailableSeats) {
+ await this.dbRepos.seatRepository.update(seatId, { active: true });
+ }
}
async deactivateSeat(seatId: string): Promise<void> {
@@ -416,4 +420,14 @@ export class UsersService {
return Boolean(seat);
}
+
+ async isClientUnderSeatLimit(clientId: string): Promise<boolean> {
+ const maxSeats = await this.getMaxAllowedSeats(clientId);
+ if (!maxSeats) {
+ return true;
+ }
+
+ const numSeats = await this.dbRepos.seatRepository.count({ where: { clientId } });
+ return numSeats <= maxSeats;
+ }
}
In this PR, there is a bug at the boundary condition. numSeats <= maxSeats is incorrect because isClientUnderSeatLimit should return false when numSeats is exactly equal to maxSeats.
In current state, the method returns true and causes a customer-facing bug where organizations can activate one more seat than allowed.
If the agent is able to create a test for this boundary condition and show that it is failing after running the test, we consider that to be an instance of "bug detection."
Test Generation Results
To illustrate the differences between the AI agents, the following section showcases the resulting test outputs for each agent.
As a reminder, we ran each AI agent on the example PR with the system message and prompt laid out above (n = 10). The following example outputs are representative of the typical test generation run.
Note that Tusk generates and runs tests on an individual level before combining them into a full test file, hence the additional granularity in the output (under "Individual Test Cases"). For the failing tests in this example, you can click to see the test execution output along with potential fixes.
Tusk (Mixture-of-Models)
Cursor Agent (Claude 3.7 Sonnet)
Cursor Agent (Gemini 2.5 Pro)
Claude Code
Comparison and Analysis
| Agent | Bug Detection | Coverage Depth | Codebase Awareness | Test Variety |
|---|---|---|---|---|
| Tusk | 90% | Covers 100% of lines in PR, average of 10.0 tests generated | Always follows existing pattern for mocking the Users and Resource services. 10% of the time it suggests test cases opposite to expected behavior. | Generates both passing tests and failing tests that are valid edge cases |
| Cursor (Claude 3.7 Sonnet) | 0% | Moderate coverage, average of 8.0 tests generated | 80% of the time it follows existing pattern for mocking the Users and Resource services. 60% of the time it suggests test cases opposite to expected behavior. | Only generates passing tests, misses edge cases. 20% of the time it finds failing tests in its thinking but excludes them from output during iteration. |
| Cursor (Gemini 2.5 Pro) | 0% | Moderate coverage, average of 8.2 tests generated | 0% of the time it follows existing pattern for mocking the Users and Resource services. 100% of the time it suggests test cases opposite to expected behavior. 40% of the time it created a test file with incorrect naming. | Only generates passing tests, misses edge cases |
| Claude Code | 0% | Fair coverage, average of 6.8 tests generated | 60% of the time it follows existing pattern for mocking the Users and Resource services. 80% of the time it suggests test cases opposite to expected behavior. | Only generates passing tests, misses edge cases |
Conclusion
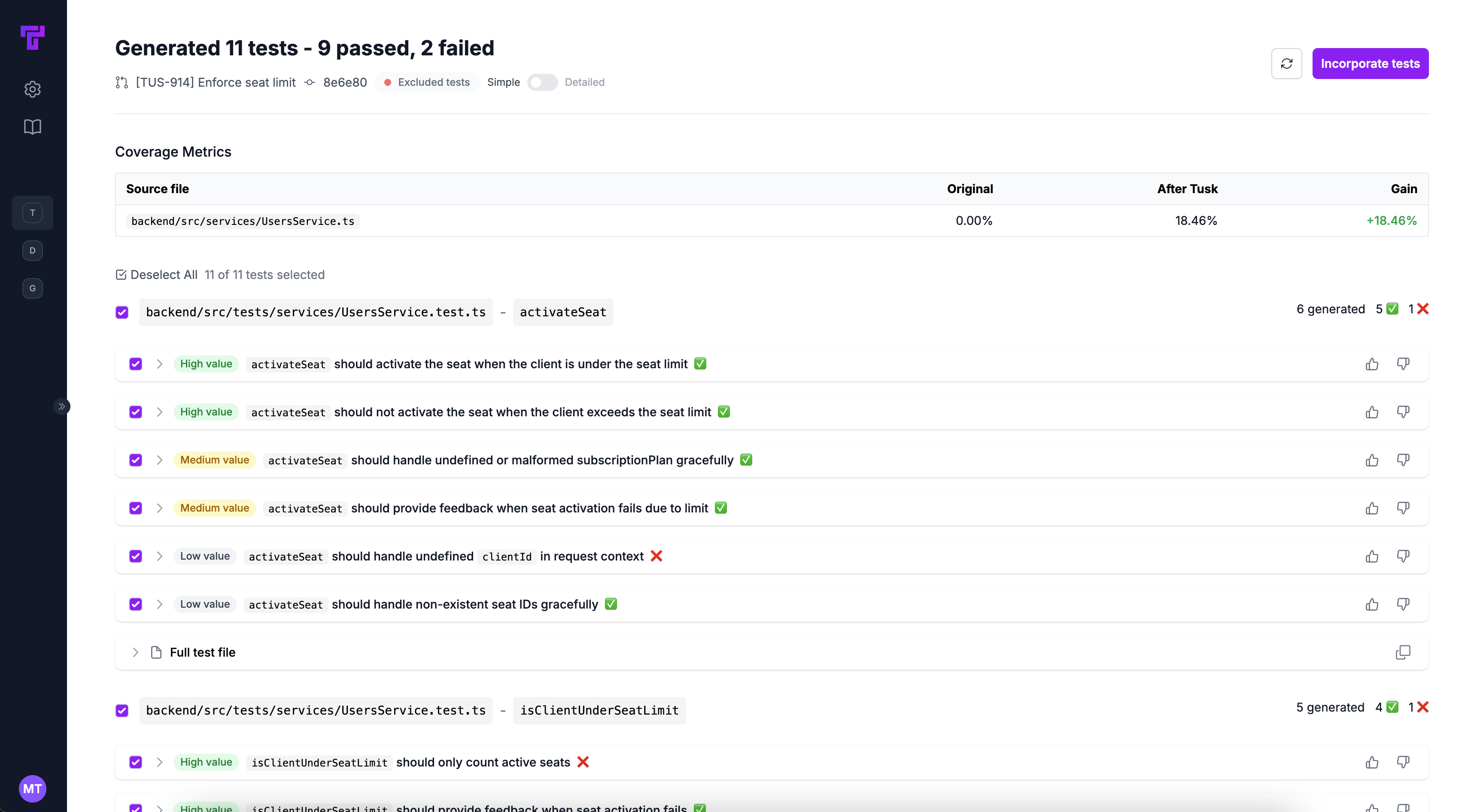
Tusk's UI showing test generation results for the example PR
While all three agents were able to generate executable test code, Tusk's test generation stood out in terms of its bug detection rate and ability to follow existing codebase patterns for mocking services.
The difference in test quality can be partially attributed to the fact that Tusk lives in the CI/CD pipeline. It is not heavily constrained by latency the way AI-powered IDEs or CLI tools are, and so is able to use more compute to reason through codebase and business context.
The Mixture-of-Models approach built into Tusk also means that our agent benefits from automatically choosing the optimal model for the specific step of the test generation process. For example, Tusk takes into account the fact that Claude 3.7 Sonnet is best-in-class at code generation, while Gemini 2.5 Pro trumps it at code editing (especially useful for working with large diffs).
I also noted other interesting auxiliary observations:
Ease of Use: Tusk runs on every push to a PR/MR's branch without any prompting required. This differs from Cursor Agent and Claude Code significantly since both are AI pair programmers that you interact with via a chat-based interface.
I found Cursor Agent to be more "uncertain" and require greater hand-holding, particularly with Gemini 2.5 Pro. On the other hand, Claude Code could confidently self-iterate before asking for more instruction. I also preferred Claude Code's UX of asking it to remember to self-run certain commands to Cursor's out-of-the-box UX of either auto-run mode or asking for confirmation every time.
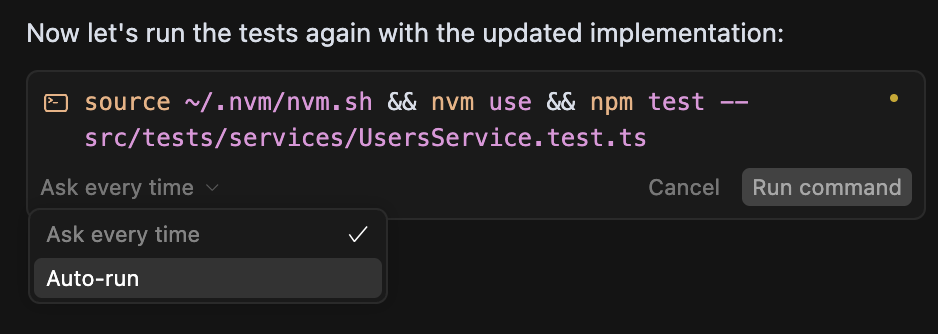
Cursor's auto-run mode for running commands
Following of Best Practices: Tusk would always find similar test files (i.e., ones using the same mocks) when retrieving context from the codebase, which made it able to consistently generate tests with the right mocking approach.
Cursor Agent also does this with its full codebase search. Like Tusk, Cursor with Claude 3.7 Sonnet demonstrated a more conservative approach, generating tests that adhere closely to existing patterns (e.g., using a
testHarnessto set up test data). In contrast, Claude Code had a tendency to be more "creative," which meant coming up with independent ways of mocking services instead of using existing patterns.
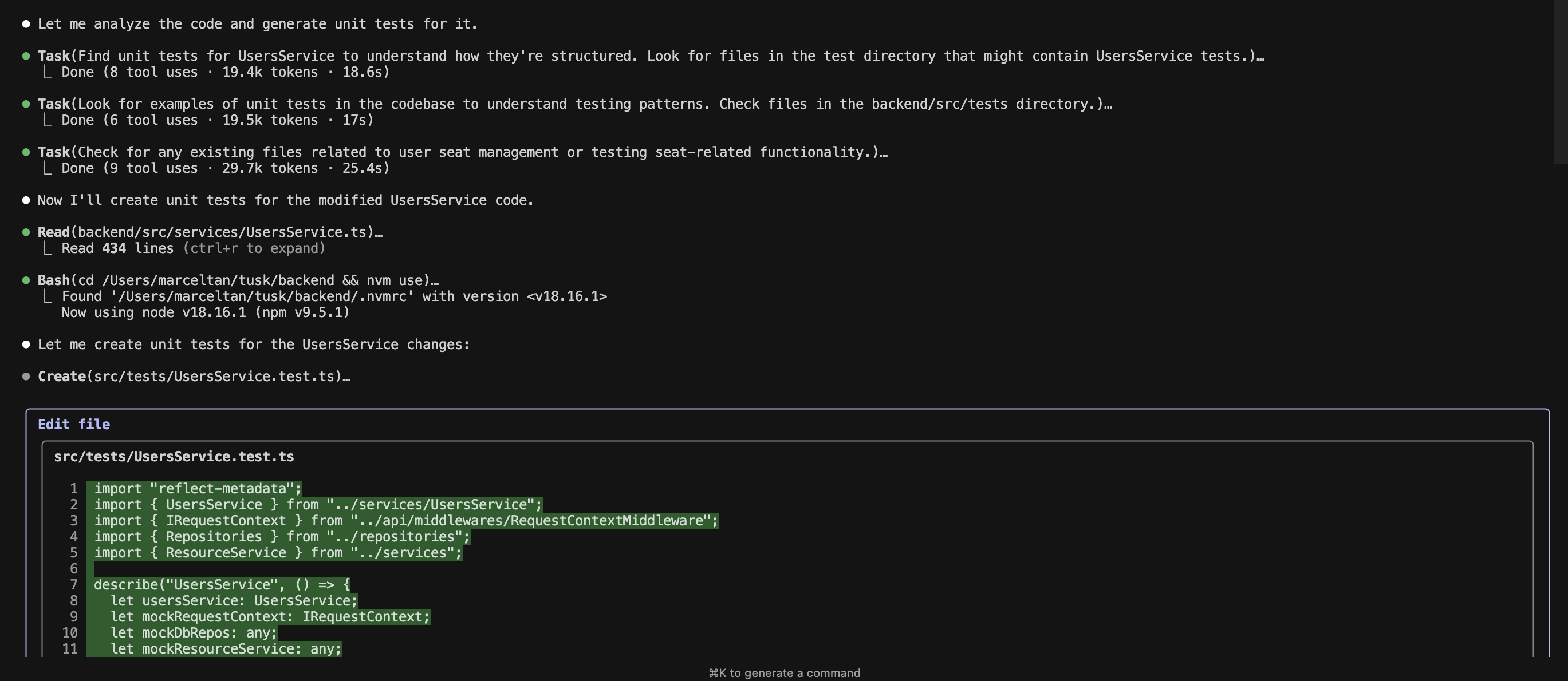
Claude Code's agentic test generation steps
Ability to Run Tests: A core part of automated testing is making sure the tests actually run. While Tusk self-runs tests perfectly every time (since this element is not agentic in Tusk's case), both Cursor Agent and Claude Code had difficulties in all attempts figuring out which directory and node version to run the tests in.
They both required additional prompting, like reminding it to run
nvm usein the backend directory before running the tests. Even with this prompting, Cursor Agent would take 3-4 iterations to generate the right bash command before it could run the tests. Claude Code was much better than Cursor Agent in this department and was usually able to figure it out on its first or second attempt.
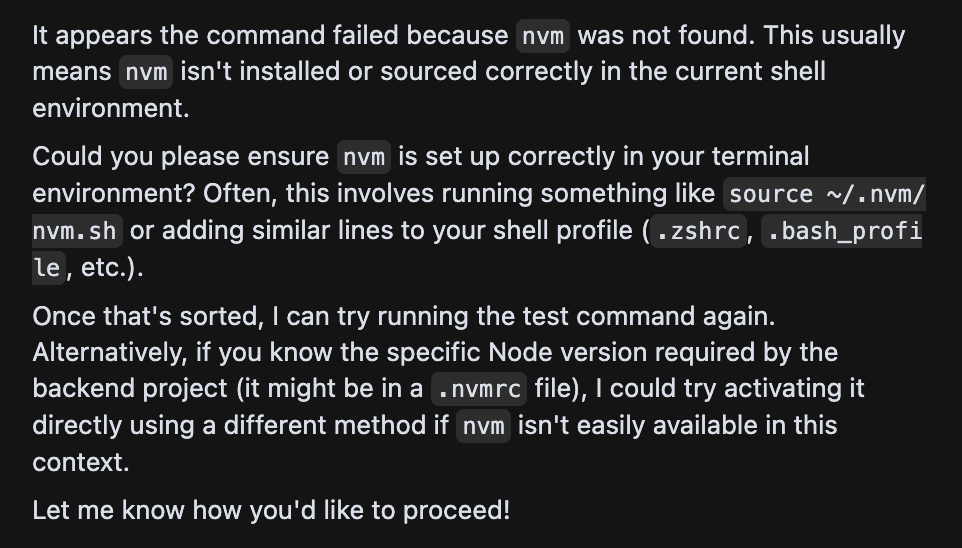
Cursor (w Gemini 2.5 Pro) having trouble running the test command
Final Note
Further Areas of Research:
Evaluate all three agents with a larger sample size of runs and PRs
Create a unit test generation benchmark along the lines of TestGenEval and TESTEVAL
Use cov@k metric, proposed in the TESTEVAL paper, to measure the diversity of the agent's generated test cases
...cov@k measures the line/branch coverage with a subset of the generated test cases with a size of k (k < M).
Propose a new metric to measure "edge case coverage," since line/branch coverage does not guarantee that edge cases are caught
This comparative analysis shows us that autonomous AI agents have advanced to a point where they can be a huge boon to software teams working on mature projects. The results beg one to imagine a "quality-first" world where no software engineer pushes code without having unit tests written.
Personally I'm very excited about engineers receiving the benefits of unit tests without the overhead of writing them manually. And while TDD may theoretically be the ideal approach, I believe the industry has come to accept that building real world products is messy and tests are often written after features are built.
Cursor Agent and Claude Code's performances show that while general-purpose AI coding agents can be helpful, they consistently miss latent bugs or affirm incorrect logic. Tusk's performance underscores the importance of using a verticalized unit testing agent to catch edge cases before they make it to production.